செயற்கையறிவு மாதிரிகள், AI model, அவற்றை பயிற்சிவிப்பது என்பது மிக விலைமதிப்புள்ளதாகவும் செலவு அதிகமானதாகவும் உள்ளது; உதாரணம் Cerebras என்ற நிறுவனம் வெளியிட்ட தகவலின்படி கீழ்கண்டவாறு செலவுகளாகிறது: இதை தனி நபர்களால் கையாளவழியில்லையெனில் :”சீசீ இந்தப்பழம் புளிக்குது!: என்று செயற்கையறிவினை பெரு நிறுவனங்களின் கைகளிலும், அரசிடமும் ஒப்படைத்துவிட்டு ஓரமாக நிற்பதா?
AI Model Training Costs – Cerebras என்ற நிறுவனம் வெளியிட்ட தகவல்
மழைபெய்தாலும் வாய்க்கால் வெட்டி, நீர் நிலைகளை பராமரித்து, ஊரனிகள் தேக்கி வயலுக்கும் தோட்டத்திற்கும் வரும் நீரை பாத்திக்குள் வரவழைப்பது ஒரு வேளான் நிபுணரின் கைவசம், வசிக்கும் ஊரின் தோலை நோக்குப்பார்வை.
இதில் லாப நோக்குடன் செயல்படுவது இன்னும் சாமர்த்தியம் – அமெரிக்காவில் இருந்து க்ஷ்ஃகொண்டு தொழில் முனைவோர் எல்லாம் பிணம்தின்னி என்றால் அது முதலாளித்துவத்தின் புரிதல் இல்லாததை மட்டுமே காட்டும்.
எது எப்படியோ நமது கதையில் ஒரு செயற்கை அறிவு என்ற ஒரு பெரு மழை பெய்து கொண்டிருக்கிறது; அதில் நம்மவர் பல துறைகளில் வல்லுநர்களாகவும், பொது நோக்கின் அடிப்படையிலும் பல இந்திரவழி செயலிகள், மாதிரிகள் (மாடல்கள்) போன்றவற்றை வெளியிட்டுள்ளனர்.
குறிப்பாக hugging face model zoo – முன்பயிற்சி செய்யப்பட்ட மாடல் முன்மாதிரிகள் உள்ளன; அவற்றில் பல தமிழ் முன்மாதிரிகள் காணலாம் தேடல் சுட்டி ; இதனை தாண்டி சுந்தர் மாமாவின் ஆட்களும் (Tensorflow Hub) மார்க் அண்ணனின் ஆட்க்களும் (PyTorch Hub) வெளியிட்ட மொழிமாதிரிகளில் பலவகை தேரும் – இவற்றையும் கையக்ப்படுத்திக்கொண்டால் சிறப்பு.
இங்கு நமக்கு என்ன வேண்டுமெனில் ஒரு பொது அளவில் எளிதாக (HW Accelerator, GPU-மாதிரி சக்தியுள்ள சில்லுகள் இருந்தாலும் மட்டும்) இந்த மாதிரிகளை கணிக்கச்செய்து நமது தமிழ் உலகில் உள்ள செயலிக்களில் சேற்றுக்கொள்ள வயப்படும்.
குறைந்த பட்சம் மொழிமாதிரிகள் (LLM – large language models, BERT போன்றவை), செயற்கை பேச்சுணரி (ASR – automatic speech recognition), செயற்கை அறிவு வழி (நரவலை வழி) எழுத்திலிருந்து பேச்சு தயாரிக்கும் பொறி (TTS – text to speech engine) ஆகிய சேவைகள் பொதுவாக
In 2022 we are reaching a point where more Tamil datasets are available than Tamil tools – arunthamizh அருந்தமிழ். However the accessibility of fully-trained models and capability of providing pre-trained models are much harder and still require domain expertise in hardware and software. Personally I have published some small Jupyter notebooks (see here), and some simple articles, but they still remain inadequate to scale the breadth of Tamil computing needs in AI world among:
NLP – Text Classification, Recommendation, Spell Checking, Correction tasks
TTS – speech synthesis tasks
ASR – speech recognition
While sufficient data exist for 1, the private corpora for speech tasks (அருந்தமிழ் பட்டியல்), the public corpora of a 300hr voice dataset recently published from Mozilla Common Voice (University of Toronto, Scarborough, Canada leading Tamil effort here) have enabled data completion to a large degree for tasks 2 and 3.
Ultimately the tooling provides capability to quickly compose AI services based on open-source tools and existing compute environment to host services and devices in Tamil space.
Proposal
My proposal is the following:
Develop a open-source toolbox for pre-training and task training specialization
Identify good components to base effort
Contribute engineering effort, testing, and validation
R&D – DataScience, Infra, AI framework
Engineering Validation – DataScience, Tamil language expertise
Engineering – packaging, documentation, distribution
Project management
Library to be liberally licensed MIT/BSD
Open-Source license for developed models
Find hardware resources for AI model pre-training etc.
Managed by a steering committee / nominated BDFL
Scope – decade time frame
TBD – மேலும் பல.
Summary
Let’s build a pytorch-lightning like API for Tamil tasks across NLP, TTS, ASR via AI.
Leave your thoughts by email ezhillang -at- gmail -dot- com, or in comments section.
Starting from my first AI application, tamil/english word classification to transitioning into a full-time AI compiler/performance engineer today I have made a career transformation of sorts; I am sharing some information from my learnings here at INFITT-2021 workshop on Keras and beginning AI apps in Tamil.
#infitt2021 தமிழ் கணிமை மாநாட்டிற்கு பயிற்சி பட்டறை அளிக்கிறேன்
AI can be biased based on training algorithms, or data, or both:
“Coded Bias” – சமுகத்தில் உள்ள ஒடுக்குமுறைகளை செயற்கையறிவில் வரையறுப்பது சரியா? #aiethics#ai-side-effects;
குப்பம்மா – உளிவீரன் அப்படின்னு பெயர்வெச்சா கடன் அட்டை கிடைக்காமல் போகவும் ராகுல், ப்ரியா என்று பெயர் வைத்தால் கிடைப்பதற்கும் உள்ள வித்தியாசம் தான் “Coded Bias” – எனில் செயற்கைஅறிவு உங்களுக்கு இது கிடைக்குமா என்ற தீர்வை கணிக்கும் நிலையில் உள்ளோம்! யாரிடம்திறவுகோல் உள்ளது?
இந்த வார பகுதியில் ஒரு வித்தியாசமான சிக்கலைப்பற்றி பேசலாம், முன்னரே எழுதிய பகுதிகளை இங்கு காண்க; அதாவது ஒரு எழுத்துணரியின் வழியாக தயாரிக்கப்பட்ட தமிழ் சொற்றொடரில் சில சமயம் மெய் புள்ளிகள் மறைந்துவிடுகின்றன. இது சற்றி இயந்திர கால சிக்கல் என்றால் அப்போது கல்வெட்டுக்களிலும் நூற்றாண்டின் நாளடைவில் இப்படிப்பட்ட சிக்கல்கள் தோன்றுகின்றன; ஆகவே இது தனிப்பட்ட ஒரு சிக்கல் இல்லை என்பதும் புலப்படுகின்றது. இந்த வலைப்பதிவில் உள்ள அல்கோரிதத்தை இங்கு ஓப்பன் தமிழ் நிரலாக காணலாம்.
1. அறிமுகம்
எனக்கு இந்த சிக்கல் இருப்பதன் காரணம், 1910-இல் ஆர்டன் பாதரியார் இயற்றிய “A progressive grammar of common Tamil,” என்ற நூலின் மறுபதிப்பு பிரதியில் சில/பல சொற்கள் விட்டுப்போயிருந்தன. மறுபதிப்பு செய்யும் நிறுவனமோ, கலிபோர்னியா லாசு ஏஞ்சலஸ் பல்கலைக்கழகத்தில் உள்ள பிரதியினில் இருந்து எப்படியோ (கூகிள் புத்தகங்கள் வழியாகவா?) ஒரு புத்தகத்தின் மின்வடிவத்தை சரிபார்க்காமல் அப்படியே அச்சு செய்து அமேசான் சந்தையில் விற்று அதுவும் என் கைக்கு கிடைத்தது. பல இடங்களில் மெய் புள்ளிகளின் மறைவு – சொற்பிழைப்போல் பாவிக்கும் இந்த பிழைகள் இந்திர வழி செயல்திருத்தத்தால் நுழைக்கப்பட்டவை. நுழககபபடடவை!
மெய் புள்ளிகளின்றி செம்புலப்பொயல்நீரார் கூற்றி சங்க இலக்கியத்தில் இருந்து இப்படியே தோன்றும்,
யாயும ஞாயும யாராகியரோ
எநதையும நுநதையும எமமுறைக கேளிர
…
இதனை எப்படி நாம் சீர் செய்வது? இதுதான் நமது இன்றைய சிக்கல்.
2. அல்கோரிதம்
உள்ளீடு
சொல் என்பதை எழுத்துச் சரமாக தறப்படுகிறது. இதனை சொ என்ற மாறியில் குறிக்கின்றோம்.
வெளியீடுகள்
மறைந்த மெய்கள் இருந்தால் அவற்றை மற்றும் திருத்தி புதிய சொல் வெளியீடு செய்வதற்கு.
அல்கோரிதம் முன்-நிபந்தனைகள்
உள்ளீட்டு சரம் என்பதில் வேறு எந்த சொற்பிழைகளும் இல்லை
சரம் என்பதின் இடம் ‘இ‘ என்பதில், சரம் எழுத்து சொ[இ] என்ற நிரலாக்கல் குறியீட்டில் சொல்கின்றோம்.
சரம் எழுத்து சொ[இ], தமிழ் எழுத்தாக இல்லாவிட்டால் அதனை நாம் பொருட்படுத்துவதில்லை
சரம் எழுத்து சொ[இ], உயிர், மெய், உயிர்மெய் (அகர வரிசை தவிர்த்து), ஆய்த எழுத்து என்றாலும் அவற்றில் எவ்வித செயல்பாடுகளையும் செய்யப்போவதில்லை
ஆகவே, சரம் எழுத்து சொ[இ] என்பது உயிர்மெய் எழுத்தாக அதுவும் அகரவரிசையில் {க, ச, ட, த, ப, ர, .. } இருந்தால் மட்டும் இதனை செயல்படுத்துகின்றோம்.
அல்கோரிதம் செயல்பாடு
மேல் சொன்னபடி, நாம் கண்டெடுக்க வேண்டியது உள்ளீட்டு சரத்தில் அகரவரிசை உயிர்மெய்களில் சரியான உயிர்மெய் எழுத்து வருகிறதா அல்லது மெய் புள்ளி மறைந்து வருகிறதா என்பது மட்டுமே!
இதனை சறியாக செய்தால் அடுத்த கட்டமாக பிழைஉள்ள இடங்களில் புள்ளிகளை சேற்றுக்கொள்ளலாம்
மேல் உள்ள 1-2 படிகளை அனைத்து சொல்லின் அகரவரிசை உயிமெய்களிலும் சயல்படுத்தினால் நமது தீர்வு கிடைக்கின்றது.
இதன் மேலோட்டமான ஒரு முதற்கண் தீற்வை பார்க்கலாம் (இதனை மேலும் சீர்மை செய்ய வேண்டும்),
அல்கோரிதம் – இதற்கு ஒத்தாசை செய்ய மேலும் கூடிய அல்கோரித செயல்முறைகளான “அகரவரிசை_மெய்”, “புள்ளிகள்_தேவையா” மற்றும் “புள்ளிகள்_சேர்” என்றவற்றையும் நாம் சேரக்க்வேண்டும்.
நிரல்பாகம்மறைந்த_மெய்_புள்ளியிடல்( சொல் )
திருத்தம்_சொல் = ""
@(சொல் இல் எழுத்து) ஒவ்வொன்றாக
விடை = 0
@( அகரவரிசை_உயிர்மெய்( எழுத்து ) ) ஆனால்
விடை = புள்ளிகள்_தேவையா( சொல், எழுத்து )
முடி@( விடை ) ஆனால்திருத்தம்_சொல் += புள்ளிகள்_சேர்( எழுத்து )
இல்லைதிருத்தம்_சொல் += எழுத்து
முடிமுடிபின்கொடுதிருத்தம்_சொல்முடிநிரல்பாகம்அகரவரிசை_உயிர்மெய்( எழுத்து )
அகரவரிசை_உயிர்மெய்கள் = 'கசடதபறயரலவழளஞஙனநமண'
பின்கொடு அகரவரிசை_உயிர்மெய்கள்.இடம்(எழுத்து) != -1
முடி
நிரல்பாகம் புள்ளிகள்_சேர் ( எழுத்து )
அகரவரிசை_உயிர்மெய்கள் = 'கசடதபறயரலவழளஞஙனநமண'
அகரவரிசைக்குள்ள_மெய் = ['க்','ச்','ட்','த்','ப்','ற்',
'ய்', 'ர்','ல்','வ்','ழ்','ள்',
'ஞ்', 'ங்', 'ன்','ந்','ம்','ண்']
இடம் = அகரவரிசை_உயிர்மெய்கள்.இடம்( எழுத்து )
பின்க்கொடு அகரவரிசைக்குள்ள_மெய்[ இடம் ]
முடி
பொதுவாக நம்மால் புள்ளிகள்_தேவையா என்ற செயல்பாட்டை சரிவர முழு விவரங்களுடன் எழுதமுடயாது. இது கணினிவழி உரைபகுப்பாய்வுக்கு ஒரு தனி கேடு. அதனால் நாம் புள்ளியியல் வழி செயல்படுவது சிறப்பானது/சராசரியாக சரிவர விடையளிக்கக்கூடிய செயல்முறை.
3. மாற்று அல்கோரிதம்
மேல் சொன்னபடி உள்ள கட்டமைப்பில் புள்ளிகள் தேவையா என்பதன் ஓட்ட நேரம் (runtime), கணிமை சிக்கலளவு (computational complexity) பற்றி பார்க்கலாம்.
உதாரணமாக, “கண்னன்” என்று எடுத்துக்கொண்டால் அது அச்சாகுமபொழுது “கணனன” என்று அச்சாகிறது என்றும் கொள்ளலாம். நமது அல்கோரிதத்தின்படி இதில் நான்று இடங்களில், அதாவது அத்துனை எழுத்துக்களுமே அகரவரிசை உயிமெயகளாக அமைகின்றன. இவற்றில் எந்த ஒது எழுத்தும் உயிர்மெய்யாக இருக்கலாம் (அச்சிட்டபடியே), அல்லது மாறியும் புள்ளி மறைந்த மெய்யாகவும் இருக்கலாம்.
அதாவது, “கணனன” என்ற சொல்லை மொத்தம் உள்ள வழிகளாவது இவற்றின் பெருக்கல்:
க என்ற எழுத்தில் இரண்டு வழிகள்
ண என்ற எழுத்தில் இரண்டு வழிகள்
ன என்ற எழுத்தில் இரண்டு வழிகள்
ன என்ற எழுத்தில் இரண்டு வழிகள்
மொத்தம் 2 x 2 x 2 x 2 = 24 = 16 வழிகள் உள்ளன.
இதனை பொதுப்படுத்தி சொன்னால்,
நீ என்ற எண் நீளம் உள்ள சொல்லில் (அதாவது, நீ = |சொல்|) என்ன நடக்கின்றது என்றால்,
நீ1 என்ற எண் சொல்லின் உள்ள அகரவரிசை உயிர்மெய்களை குறிக்கும் என்றால்,
நீ1 ⩽ நீ,
மொத்தம் நாம் பரிசோதிக்க வேண்டிய வழிகள், 2நீ1
இது விரைவில் பொறிய அளவு வளரும் ஒரு தொகை, இதனை exponentially fast, அதிவேகமாக வளரும் கணிமை என்றும் சொல்லாம். இதற்கு என்ன செய்ய வேண்டும் என்றால் இதனை எளிதாக வழிகள் தோன்றும் படி மட்டும் விடைகள் தேடினால் நமது செயல்பாடு விரைவில் முடியவே முடியாது – இதற்காக branch and bound என்ற செயல்முறைகளை பயன்படுத்தவேண்டும்.
#இந்த நிரல்பாகம், 2நீ1 என்ற ஓட்ட நேரத்தில் இயங்கும்
நிரல்பாகம் புள்ளிகள்_தேவையா_உதவியாளர்( முதல்_ஒட்டு, சந்தித்காதவை )@( நீளம்( சந்தித்காதவை ) == 0 )பின்கொடு [முதல்_ஒட்டு]முடி
விடைகள் = []
எழுத்து = சந்தித்காதவை[0]
@( அகரவரிசை_உயிர்மெய்( எழுத்து ) ) ஆனால்
#உள்ளபடியே இந்த இடத்தில் மெய் இல்லை என்றவழியில் யுகிக்க
விடைகள்1 = புள்ளிகள்_தேவையா_உதவியாளர்(முதல்_ஒட்டு + எழுத்து, சந்தித்காதவை[1:])
விடைகள்.நீட்டிக்க( விடைகள்1 )
#உள்ளபடியே இந்த இடத்தில் மெய் வந்தால் எப்படி இருக்கும் என்ற்வழியில் யுகிக்க
மெய்எழுத்து = புள்ளிகள்_சேர்(எழுத்து )
விடைகள்2 = புள்ளிகள்_தேவையா_உதவியாளர்(முதல்_ஒட்டு + மெய்எழுத்து, சந்தித்காதவை[1:])
விடைகள்.நீட்டிக்க( விடைகள்2 )
இல்லை
விடைகள்3 = புள்ளிகள்_தேவையா_உதவியாளர்(முதல்_ஒட்டு + எழுத்து, சந்தித்காதவை[1:])
விடைகள்.நீட்டிக்க( விடைகள்3 )
முடி
பின்கொடுவிடைகள்முடிநிரல்பாகம் மறைந்த_மெய்_புள்ளியிடல்(சொல்) #யுகிப்பு சார்பு என்பது n-gram புள்ளியியல் கொண்டு #சொல்லின் புள்ளிகள் சோர்க்கப்பட்ட மாற்றங்களை மதிப்பிடும்.மாற்று_சொற்கள் = புள்ளிகள்_தேவையா_உதவியாளர்( '', list(சொல்) ) மதிப்பீடுகள் = யுகிப்பு_சார்பு( மாற்று_சொற்கள் )
இடம் = அதிக_மதிப்பெண்_இடம்( மதிப்பீடுகள் )
சரியான_மாற்று_சொல் = மாற்று_சொற்கள்[ இடம் ]
பின்கொடு சரியான_மாற்று_சொல்
முடி
மேல் சொல்லப்பட்டபடி கணினி அல்கோரிதப்படுத்திப்பார்த்தால் ‘கணனன’ என்ற சொல்லிற்கு, 16 மாற்றுகள் கிடைக்கும். அவையாவன,
இந்த சமயம் நமக்கு சரியான விடைகிடைக்கவில்லை; இதனுடன் அகராதிபெயர்கள் அல்லது classification செயற்கைப்பின்னல்களை பயன்படுத்திப்பார்க்கலாம் என்றும் தோன்றுகிறது.
இந்த அல்கோரிதத்தை ஓப்பன்-தமிழ் பைத்தான் நிரலாக எழுதினால் இப்படி:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
இனிய புத்தாண்டு வாழ்த்துக்கள் 2020. செயற்கையறிவு – சில கட்டமைப்பு பயிற்சி சுட்டிகளை இந்த பதிவில் நான் பகிர்கின்றேன். எனது குறிக்கோள் என்னவென்றால் – இதனை படிக்கும் நீங்கள் பைத்தான், numpy, tensorflow என்ற நுட்பங்களையும் கட்டமைப்புகளையும் கையாண்டு செயற்கையறிவு திறண்களை ஒரு ஆண்டில் அல்லது குறைவான காலத்தில் நீங்கள் பெறலாம் என்பதாவது. இவை அனைத்தையும் கற்றிட ஒரு கூகில் கணக்கு மட்டும் இருந்தால் போதும் – அவர்களது colaboratory = code + laboratory என்ற இணைய சேவை மிக உதவிகரமானது – இங்கு பார்க்கவும்.
முதலில் உங்களுக்கு பைத்தான் மற்றும் numpy, அணிகளின் கணிதம் (linear algebra – எனுக்கு மிகவும் பிடித்தவர் பேராசிரியர். கில்பட் ஸ்டிராங்.) ஒருபடியாக தேர்ச்சியடைந்திருந்தால் நல்லது. இல்லாட்டி வருத்தப்படாமல் கூகில் செய்யுங்க; StackOverflow செய்யுங்கள்.
மேலும் படி 2-இல் சிக்கல் நேர்ந்தால் அல்லது உங்களுக்கு அதிக அளவு விவரங்கள் தேவைகள் இல்லாவிட்டால் Keras என்ற கட்டமைப்பையும் பயன்படுத்திடலாம். இவை இரண்டும் இல்லாத மற்ற கட்டமைப்புகளான PyTorch மற்றும் Caffe, CNTK என்றும் உள்ளன – இவற்றை பற்றி சொல்வதற்கு எனக்கு தேர்ச்சி இல்லை;
உங்களுக்கு படிப்பதற்கு இவற்றில் ஏதோ ஓன்றினை மற்றும் படித்தால் போதுமானது; அதாவது இவற்றினிடையே வித்தியாசங்கள் எல்லாம் குளிர்பானங்களினிடையே உள்ள வித்தியாசங்களினை மட்டும்தான் என்ற்படி உணரவேண்டும்; நீங்கள் இந்த பலவிதமான செயற்கையறிவு கட்டமைப்புகளினிடையே காணமுடியும் என்றும் சொல்லாம்.
தமிழில் ஒரு முதல் முறையாக சென்ற ஆண்டு வெளிவந்த நூல் “எளிய தமிழில் Machine Learning,” கணியம் திருமதி. து. நித்தியா. இதனை கிண்டில் மின்கருவி/செயலி அல்லது PDF-இலும் இங்கு படிக்கலாம்.
எது செய்தாலும் நீங்கள் பயிற்சி நோக்கில் செய்பட எனது வலியுருத்தல். ஏட்டு சுறைக்காய் கறிக்கு என்றும் உதவாது என்றும் நாம் அறிவோம். மேலும் பயிற்சி செய்து சான்றுகள் பெற இணைய வழி பல்கழைக்கழாக்ங்களும் உதவுகின்றன – Coursera, Udacity போன்றவை.
இந்த செயற்கையறிவு நிரல்களை கொண்டு சில 5 ஆண்டுகளுக்கும் முன்பு எவராலும் இயல்முடியாத செயல்களை இந்த செயற்கை நரம்பு பின்னல்கள் (Deep Neural Networks) என்பவை சாத்தியப்படுத்துகின்றன. இந்தியாவில் இதை எழுதும் சமயம் 50% மேலான மக்கள் 30 வதிற்கும் குறைந்தவர்கள் – இந்த வழி திறண்களைக்கொண்டு புதிய சேவைகளையும் பலதுரைகளின் உருவாக்கியும் வழங்கியும் வாழ்வினை செம்மைப்படுத்தலாம்.
உதாரணம்:
தானியங்கி கார்கள்/வாகனங்கள் செயல்படுத்துதல்: Tesla, Waymo, Cruise போன்ற பல நிறுவனங்கள் இவற்றினை செயல்படுத்துகின்றனர்.
கணினி காட்சி அறிவியல்/உணர்தல்: ImageNet என்ற பல மில்லியன் படங்கள் கொண்ட தறவில் இருந்து பயிற்சி செய்யப்பட்ட செயற்கை நரம்பு பின்னல் 1000-வகையான பொருட்களை மனிதர் திறன் காட்டிலும் துல்லியமாகக் கண்டறிய உதவும். இவற்றைக்கொண்டு என்ன செய்யலாம் – யோசியுங்கள் ?
மொழியில் சேவைகளும் NLP கணினியில் செம்மைபடுத்த இவைகள் உதவும்;
இந்திய அழகியல் – விருந்தினர்கு வரவேர்ப்பறை விளக்கு. புதிய தொடக்கம்.
ஊருக்கு உபதேசம் இல்லாமல், தங்களது சேவைகளின் பயன்களை தாமே முதலில் பயன்படுத்துவதை ‘Eating your Dog Food‘ என்று கணினியாளர்கள் மத்தியில் பேசப்படுவதாவது.
இதன்படி தமிழ்கணிமைக்கு உதவும் வகையில் நேரடியாக தானியங்கி, செயற்கையறிவு சேவைகளை முதலில் தனது பயன்பாட்டிற்கு தமிழ் கணினியாளர்கள் கையாளவேண்டும்.
எனது பார்வையில் முதல்படி தேவைப்படும் சேவைகளானது:
தானியங்கி வழி, கணினி உதவி ஆவனங்கள், பயிற்சி நூல்களை (training, tutorial manuals) மொழிபெயர்ப்பது
இந்த நூல்கள் அனைத்தும் சில கலைச்சொற்கள் தவிர மற்ற்வை அனைத்தும் ஒரே கோனத்தில் இருப்பவையாகின்றன. தானியங்கி மொழிபொயர்ப்பு செயலிகள் சரியனவையாக அமையும்.
இதன் முக்கியத்துவத்தை அதிகப்படுத்தி சொல்லமுடியாது. ஒவ்வொரு கலைசொல் அடங்கிய புத்தகமும் வெளிக்கொண்டுவர பல மாதங்களில் இருந்து சில ஆண்டுகள் ஆகின்றன – இந்த கால தாமத்தை குறைக்க வேண்டும்.
முக்கியமாக எனது பார்வையில் இந்த நூல்கள் விரைவில் தமிழாக்கம் ஆகவேண்டும்
TensorFlow செயற்கையறிவு மென்பொருள் கட்டமைப்பு உதவி ஆவணங்கள்
வீடியோ வழி, ஒலி வழி – உரை, கட்டுரை, நூல்கள் உருவாக்க செயற்கையறிவு செயலிகள்
தமிழில் கணினி சார்ந்த தகவல்களை தமிழ் கணினியாளர்கள் நேர்வழி பங்களிப்பதும் பயன்படுத்துவதற்கும் ASR, OCR, Video close-captioning, போன்ற செயல்பாடுகள் பலரையும் தமிழ்கணிமைக்குள் வரவேர்க்க உதவும்.
புதிய கருத்துக்களையும், புதிய தகவல்களையும் தமிழிலேயே உருவாக்க இது உதவும்
செயற்க்கையறிவு அணிமாதிரிகளை பொதுவாக “Model Zoo” என்று அருங்காட்சியகமாக பயன்படுத்துவது.
தமிழுக்காக பலரும் தங்களது செயற்கையறிவு கருவிகளை உருவாக்குகின்றனர். இவற்றில் பயிற்சி செய்வது ஆகக்கடினமானது, அதிக நேரம் கணிமை செலவெடுக்கும் வழியில் ஆனது. எனவே இவற்றை முடிந்த அளவில் பொதுவெளி (public domain) உரிமத்தில் வெளியிடல் சிறப்பானது
தமிழ் அகழாய்வு பற்றிய உதவி செயலிக்கள் (சற்று திசைமாரி மேல் சொன்னமாதிரி இந்த பயன்பாடு கணிமைக்கு நேர்வழி உதவாதது என்க்கு புலப்படுகின்றது)
ஒரு பானை ஓட்டில் எழுதப்பட்ட சொல் தமிழ், தமிழி (பிரமி), அல்லது எண்களா? அல்லது எழுத்துக்களா? என்பதனை கண்டறிய பொதுமக்கள் கைபேசியில் சொயலிகளின் வழி நிறுவி தொல்லியல் வல்லுநர்களுக்கு சிறந்த சரியான தகவல்கள் அளிக்கும் வகை இந்த செயலிகள் உதவும்.
மேலும் தமிழ் மொழி கல்வி, சிந்தனைக்களம், தகவல் பரிமாற்றம் போன்றவற்றைப்பற்றி நீங்களும் சிந்தியுங்கள் – கருத்துக்களை இந்த வலையில், அல்லது மின் அஞ்சலிலும் பதிவிடுங்கள்.
One problem that seem to not draw interest from various actors in digital Tamil community seems to be the Tamil input via 4 x 3 standard Keypad.
A standard 4×3 keypad shown with digits and letters, including Japanese key entry on a vodafone device. Image credits to Wikipedia.
Problem Statement: Given a 4×3 matrix of keys in a phone keypad, how can we input the basic 13 + 18 + 12×18 = 247 letters of Tamil alphabet using this device ?
Alternate: Clearly, 247 letters have an information content of bits or roughly 8bits. So we can simply punch in 3 keys for indicating this 8bit combination and we are done. Provide a table to the user about 247 letters and their 3-numeric key map and we have solved this problem in one way.
This is not very satisfying however; we seem to put the user to more work; we would instead like to have similar entry method in Tamil just like in English (where 3 letters are grouped per telephone key). The processor for application in the phone or mainframe can decode any ambiguity of the telephone keypad mapping into meaningful words or phrases.
Ideas: We can come up with various proposals; being lazy, and the official jester of Tamil computing community, I will try and make a simple combinatorial analysis for this problem without giving a specific solution.
Details: We can consider the factors of 247 = 19 x 13 which form a matrix of all letters representing the Tamil alphabets and we can count the partitions of this matrix onto the smaller keypad matrix. Following the roman letters of English alphabet consisting of 26 letters are fit easily into the 4 x 3 matrix on average of little less than 3 letters per key, we can also adopt a similar convention.
There are many ways to fit this large 19 x 13 matrix into a 4 x 3 matrix. Using simple combinatorial analysis we may show 19 letters can be divided into 4 groups as (ignoring the assignment of letter groups to keys – ways) along the rows. Similarly, we group along columns in ways (and ignoring the 3! column permutation themselves). In all we have a total of key grouping combinations.
Clearly we have an alternate possibility of grouping the 19 x 13 matrix as a transposed matrix – i.e grouping dimension of 13 elements of Tamil alphabets into larger keypad dimension of 4, and assigning 19 elements along the fewer keypad dimension of 3. This alternative gives us
Together we have a total of 1,801,371. Thats roughly 1.8 million possibilities! Check them yourself by running this code:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
. The real grand total of possible designs is to include the key permutations of the grouping we have already found, thereby adding a factor of to the previous 1.8 million so we get grand total of keypad mapping designs as 259,397,424 or 259 million keyboard combinations in all!
Conclusion: How are we going to find a suitable keypad mapping? Well we may need more heuristics and more cleverness to find the keypad mappings [a few definitely exist in this 259 million possibilities, which maximize a utility function.
So that leads us to the next problem: what is the utility of mapping a Tamil letters in the keypad ? Well – we don’t know apparently, so it doesn’t exist! This also ties into the philosophical question of what is the purpose of all software if not to support use.
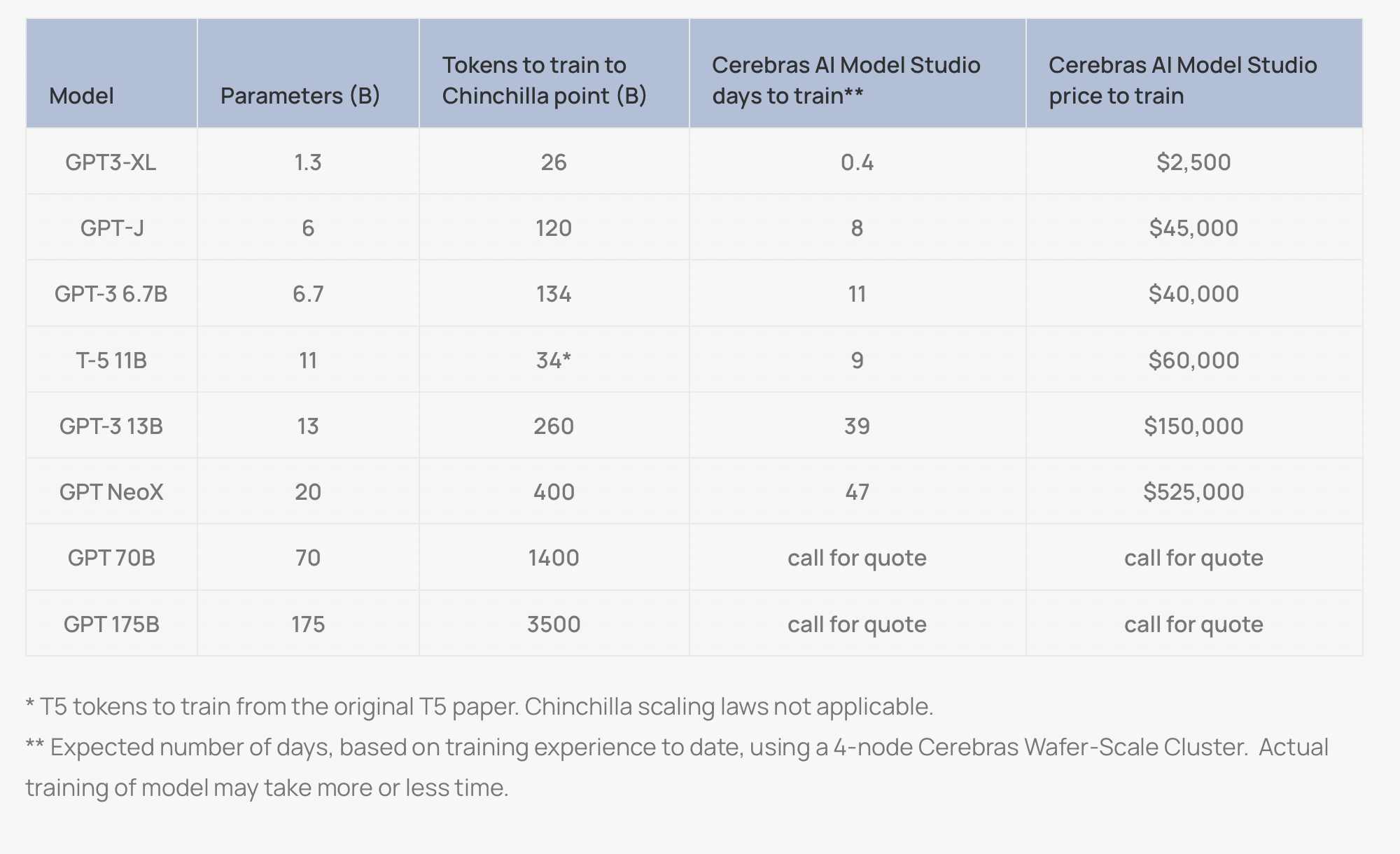







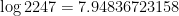 bits or roughly 8bits. So we can simply punch in 3 keys for indicating this 8bit combination and we are done. Provide a table to the user about 247 letters and their 3-numeric key map and we have solved this problem in one way.
bits or roughly 8bits. So we can simply punch in 3 keys for indicating this 8bit combination and we are done. Provide a table to the user about 247 letters and their 3-numeric key map and we have solved this problem in one way. (ignoring the assignment of letter groups to keys –
(ignoring the assignment of letter groups to keys –  ways) along the rows. Similarly, we group along columns in
ways) along the rows. Similarly, we group along columns in 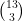 ways (and ignoring the 3! column permutation themselves). In all we have a total of
ways (and ignoring the 3! column permutation themselves). In all we have a total of  key grouping combinations.
key grouping combinations.
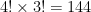 to the previous 1.8 million so we get grand total of keypad mapping designs as 259,397,424 or 259 million keyboard combinations in all!
to the previous 1.8 million so we get grand total of keypad mapping designs as 259,397,424 or 259 million keyboard combinations in all!
