சென்ற பதிவை எழுதியபின் சிறிது நாடகளில் சொல்வனம் தளத்தில் இருந்து எனக்கு அவர்களின் தரவு கிடைத்தது. இதனை MySQL வடிவில் உருவாக்கி மேலும் அதனை ODBC போன்ற அனுகுமுரைகளின் வகையால் Python நிரல் மூலம் இந்த இதழின் வழி வந்த கட்டுரைகளை மொழியியல் ஆய்விற்கு கொண்டுவரலாம். ஆனால் இதனை செய்ய முதல்படியை கூட இன்னும் தாண்டவில்லை. MySQL மரு நிறுவுதல் சற்று சிக்கலாக உள்ளது.
இந்த பதிவில் விட்டர்பீ அல்கோரிதம் (Viterbi algorithm) என்பதனை கொண்டு எப்படி சொற்பிழைகளை திருத்தலாம் என்பதை மேலோட்டமாக பார்க்கலாம். முழுவிவரங்கள் இங்கே. விட்டர்பீ அல்கோரிதம் என்பது தகவல்தொழில்னுட்பத்தில் பிழைகளை நீக்கும் வண்ணம் வடிவமைக்கப்பட்ட ஒரு மிக முக்கியமான உத்தி/கண்டுபிடிப்பு. இது ஒரு குறியீட்டின் (code), பிழைகளை அந்த குறியீடு எப்படி உருவானது என்ற state-transition-table கொண்டு பிழைகளை நீக்கும்.
இதனை எப்படி மொழியில் சொற்பிழைகளை திருத்த பயன்படுத்துவது ? இதோ இப்படி – இந்த முழு கட்டுரையை பார்த்து தான் நானும் மயங்கினேன். அதாவது மொழியின் 1-கிராம், 2-கிராம், 3-கிராம் ஒலி எண்களின் மாற்றங்கள் புள்ளிவிவரங்களை (ngram state-transition tables) கொண்டு மட்டுமே இதனை சாதிக்க முடியும் என்று Etsy பொறியாளர்கள் சொல்லினார்கள் – அதை நானும் ஒப்புக்கொள்கின்றேன்.
இது சற்று தகவல் தொழில்நுட்பத்தின் சாஷ்டாங்க வழிகளினில் இல்லாவிட்டாலும் மொழியின் கட்டமைப்பை இலக்கணம் வழி இல்லாமல் புள்ளிவிவரத்தின் வாயிலாக எடுத்துக்கொள்ளலாம்.
இந்த பூனைக்கு யார் மணிகட்டுவாங்க ? 🐈





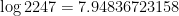 bits or roughly 8bits. So we can simply punch in 3 keys for indicating this 8bit combination and we are done. Provide a table to the user about 247 letters and their 3-numeric key map and we have solved this problem in one way.
bits or roughly 8bits. So we can simply punch in 3 keys for indicating this 8bit combination and we are done. Provide a table to the user about 247 letters and their 3-numeric key map and we have solved this problem in one way. (ignoring the assignment of letter groups to keys –
(ignoring the assignment of letter groups to keys –  ways) along the rows. Similarly, we group along columns in
ways) along the rows. Similarly, we group along columns in 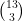 ways (and ignoring the 3! column permutation themselves). In all we have a total of
ways (and ignoring the 3! column permutation themselves). In all we have a total of  key grouping combinations.
key grouping combinations.
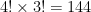 to the previous 1.8 million so we get grand total of keypad mapping designs as 259,397,424 or 259 million keyboard combinations in all!
to the previous 1.8 million so we get grand total of keypad mapping designs as 259,397,424 or 259 million keyboard combinations in all!




