Recently, as part of Ezhil-Language-Foundation, we offered a registration support ($25) for upto 10 individuals to attend the Tamil Internet Conference in Thanjavur, India (Dec 15-17th, 2022).
Seeking Applications
We created a simple setup with google form to request applications; some of the questions were,
Brief introduction about your profile
Why do you want to attend the conference
Will you be able to travel to the venue
Your open-source or published works
Areas of interest in Tamil computing
R&D software
R&D literature, culture, society
Pedagogy
etc.
We shared the URL to this applications across multiple forums like Thamiza free-tamil-computing mailing list, Tamil Linux Forums, few WhatsApp groups dedicated to INFITT, and Open-Source Tamil computing
Shortlist
We received 8 applications, with 2/3 of men and 1/3 women, they were all notified by the team on receipt of the application; of the 8 we found only 6 candidates were able to travel and interested in the mission of the conference and aligned with Ezhil Language Foundation mission.
We attempted to keep the selected candidates to be gender balanced and sensitive to Diversity Equity and Inclusion (DEI) mission objectives of Ezhil Language Foundation.
The accepted candidates were notified of their sponsorship to the conference registration and asked to prepare for the travel.
Conference Days
None of the selected 6 candidates attended the conference!
Problems
In this blog post we like to analyze why people were not able to attend the conference despite our sponsorship of the registration:
Communications
Communications were purely conducted by email and people were not sure about the program objectives
Candidates were not able to make travel arrangements since the financial sponsorship news came in quite late – 1 week before conference date.
Candidates expected some form of financial aid sent to them via digital payments (PayTM, UPI etc.)
Financial Reasons
Candidates expected a “full ride” (stay/accomodation, travel, and registration) for the conference.
Accomodation/Distance/Travel logistics
All selected applicants expressed concern regarding their inability to travel at short notice and were not familiar with the digital format to attend the conference
Ezhil Language Foundation did not sponsor candidates who were interested in attending the conference remotely
Summary
We would like to thank all applicants to the conference sponsor program; we strive to learn from the experience and make a better program for the next/upcoming year. We also thank the various members instrumental to share the message about the program into
Future conference sponsorship should be designed to avoid such a nil-outcome; the motivation for sending a mix of younger (new) and older (experienced) participants to a conference is to enable networking and cross-pollination of ideas, and support the mission of Ezhil Language Foundation – to secure the future of Tamil in the digital realm.
If you have better ideas, comments, criticisms on the program please email: ezhillang@gmail.com
We contend creation of new AI/ML applications in Tamil is still hard despite relative abundance of Tamil datasets [1]; this is due to scarcity of Tamil tools. However the accessibility of fully-trained models and capability of providing pre-trained models, like huggingface [2], are much harder and still require domain expertise in hardware and software.
While individuals have have published [3-4] some small Jupyter notebooks, and articles, but they still remain inadequate to scale the breadth of Tamil computing needs in AI world among:
NLP – Text Classification, Recommendation, (2) Spell Checking, (3) Correction tasks, TTS – speech synthesis tasks, and ASR – speech recognition
While sufficient data exist for 1, the private corpora for speech tasks (அருந்தமிழ் பட்டியல்), the public corpora of a 300hr voice dataset recently published from Mozilla Common Voice (University of Toronto, Scarborough, Canada leading Tamil effort [5a]) have enabled data completion to a large degree for tasks 2 and 3. Private repositories exist for voice data under Penn LDC.
Ultimately the missing tooling can provide capability to quickly compose AI services based on open-source tools and existing compute environment to host services and devices in Tamil space. We propose for community to build a pytorch-lightning [5b] like API for Tamil tasks across NLP, TTS, ASR via AI so that newer AI/ML applications are easily built. Role of central institutions and governments is also explored.
1 Introduction
Recently, DALL-E images (Generative AI) by Open-AI, and Stable Diffusion models by Emad Mostaque of Stability AI provides promise generative capabilities to average users unleashing creativity (Fig. 1). These tools and technologies provide pathways to adapt some fast AI applications for good (provide TTS in voice of disabled person who has lost voice) and nuisance, or mischief (fake-news) etc. Generative AIs have their unresolved problems we list under biases portion of this paper.
AI technologies allows several applications for Tamil community but we have report that adapting them safely and creatively with positive outcomes require more work from side of tooling, data curation among other metrics.
Fig. 1: Prompt to DALL-E from OpenAI [6] describing (a) street temple-car festival (Thiruvizha) in Madurai at night; (b) Tamil family celebrating festival of lights Deepavali in Madurai; same for bottom row as well. The prompt asked AI to generate in pastel style.
2 Models
Traditionally, Machine Learning Models were built for specifics – Specific Task, Specific Language – like Text Classification for English, Text Classification for Tamil and so on. Recently, Since the rise of Transformer-based models like BERT, The lines of these specifics have gotten blurred. Thanks to Large Language Models that are trained on huge datasets and Millions and Billions of Parameters, The same model that’s used for English Translation can also be used for Tamil Translation.
2.1 Zero-Shot Usage
Zero-shot learning is a machine learning technique that allows a model to recognize an object or a concept that it has never seen before. While many, if not most, machine learning models require a large amount of training data, zero-shot learning can recognize an object or concept without any new training data. Large Language Models are trained on a large amount of text data. These models can be used to answer questions about text, such as “what is the most likely next word in a sentence?” Hence these models work fairly good out-of-box making them ideal candidates for a good Zero-shot usage.
An example of a Zero-shot usage is to use a Large Language Model like GPT-3 for Sentiment Classification for Tamil Language. Thus eliminating the need for new training data.
2.2 Model Fine-Tuning
Model Fine-tuning is a technique that allows a model to be trained on a new dataset. Large Language Models or Foundational Models can be fine-tuned to get improved performance on a new dataset. This became quite popular since the beginning of Transfer Learning. Transfer Learning is the process of applying knowledge gained in one context to a different context. For example, if you have learned how to use Microsoft Word, you can apply that knowledge to using OpenOffice. In the same way, Foundational Models or Large Language Models trained for Text Generation tasks can be used for other applications like Sentiment Analysis, Entity Extraction, Grammar Correction and so on.
While Zero-shot Learning can work fairly well in a general context and is good for the English language, It can improve the performance of these models very well if they get trained on a relatively smaller dataset. Fine-tuning a Large Language Model to let the fine-tuned model perform NLP for the dataset that is similar to the fine-tuned dataset can be a very effective way to use Foundational LLMs for Tamil NLP tasks.
This does not mean that these models cannot be used in Zero-shot capability but means they do a lot better if they are fine-tuned on relevant dataset which in our case is new Tamil Dataset.
2.3 Model Serving
One of the least addressed problems in ML and AI is how to serve the Model to developers and end-users. It is important that we serve both Developers, who would build on top of our toolkit and end-users who would directly use our toolkit to leverage AI/ML for their Tamil NLP requirements. Hence we propose two distinct ways to serve these models as a central toolkit for Tamil AI/ML
A Python Library for Developers
A Gradio App
The Python Library that can be hosted for free on PyPi can serve the Tamil developers who want to use our Toolkit to build applications and services leveraging Tamil AI/ML while the Gradio App that can be run locally on any computer (preferably GPU) or hosted for free on Hugging Face Spaces can serve the end-users like Tamil Content Creators who want to include our Toolkit as part of their workflow.
2.4 Model Selection
While there is a growing number of Large Language Models every single day, It’s very important for us to pick the right model that can work well for Tamil Language. One of the easiest ways to select the right model for Tamil is by looking at the training dataset information.
Most open source Large Language Models indicate their training dataset composition. From that information, We can understand which of those existing Large Language Models have got the most Tamil Data during the Model Training. This is primarily applicable for a Zero-shot Learning since Fine-tuned models mostly would have been fine-tuned on Tamil Dataset.
For example, Big Science’s BLOOM model was 46 Natural Languages and 13 Programming Languages. Tamil is one of those Natural Languages of the Indic category which is ~4% of all the languages. Even though Tamil is a very small part of the entire language set, The Zero-shot tasks like Text Generation that we experiment for Tamil works fairly fine.
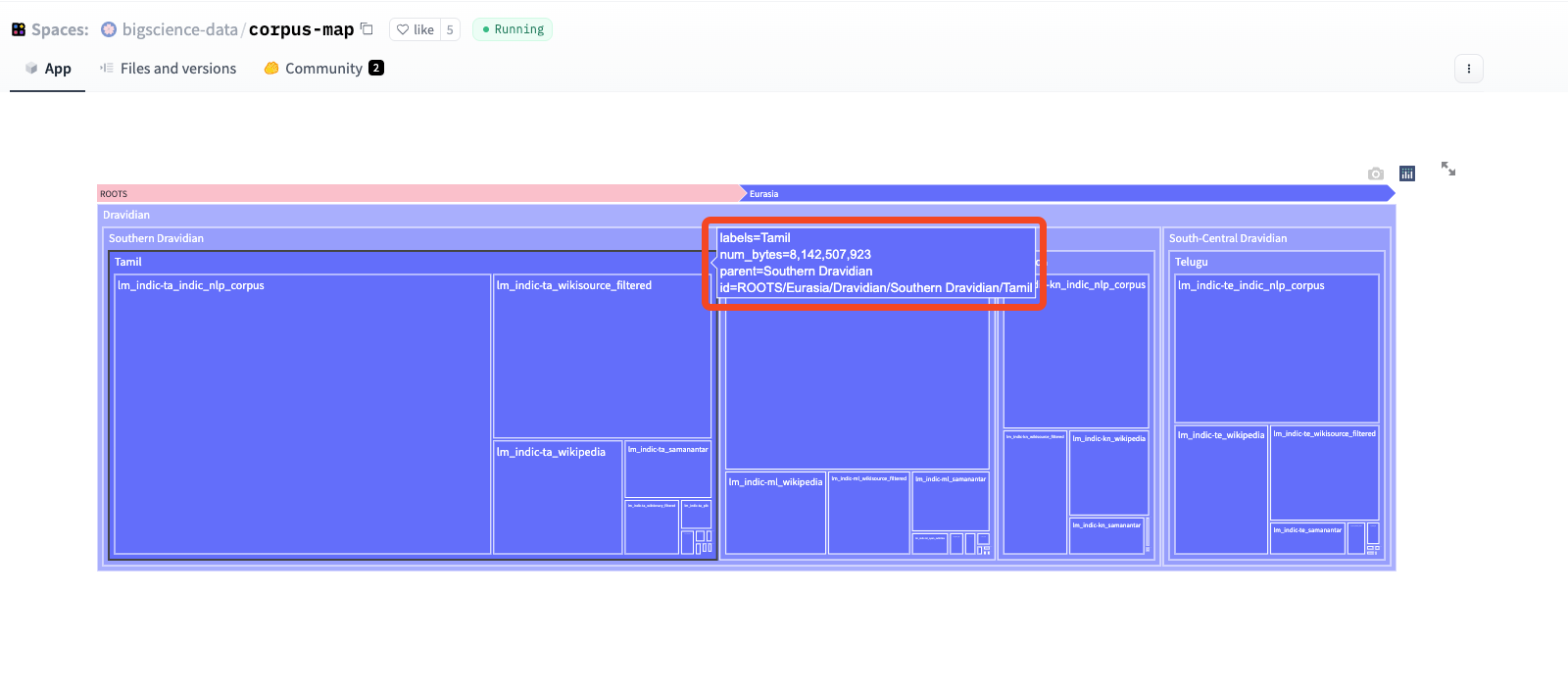
Fig. 2: Corpus map used to train a specific model [7]
BLOOMZ and mT0, a family of models capable of following human instructions in dozens of languages zero-shot. BLOOMZ and mT0 are finetuned from BLOOM and mT5 pretrained multilingual language models on crosslingual task mixture (xP3) and the resulting models are capable of crosslingual generalization to unseen tasks & languages. In the case of BLOOMZ & mT0, Tamil is just 0.5% of the fine-tuned data, Yet the model is capable of performing tasks like Sentiment analysis, Text generation, Keywords creation and so on.
3 AI Applications for Tamil
RoBERTa and BERT models are customized for Tamil by finetuning the final layers for classification of idioms in work [17]. We report in this section how various NLP, TTS applications can be solved using AI/ML models.
3.1 Spelling Correction with LLM
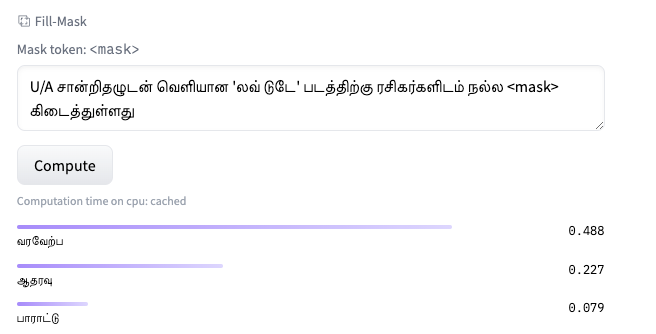
We may use masked words as ‘<mask>’ when input sentence to check for spelling correction on certain words in sentence that are out-of-dictionary or not correctable by known rules [8];
Fig. 3.1: Spelling checker functionality of LLM using masking; missing word is recommended வரவேற்பு.
3.2 Sentiment Recognition with LLM
Sentiment Recognition in NLP is the task of identifying the correct sense of a word in a given context. This is one of the most used tasks in NLP given how much text data is available in the world. It’s also largely sought after given the business applications of Sentiment Analysis Models.
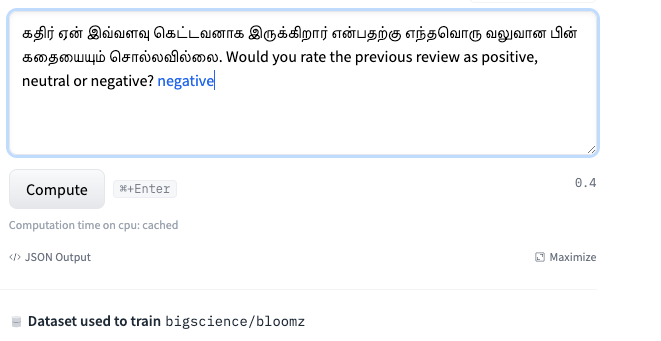
Fig. 3.2: sentiment recognition of text by using LLMs.
With the help of LLMs, We can use the existing Foundational models for Sentiment Analysis in Tamil Language without the need for a new training dataset. For example, We used BLOOMZ LLM for performing Sentiment Analysis of a Tamil Review in a Zero-shot Context.
3.3 Named-Entity Recognition with LLM
Named-Entity Recognition is the task of identifying the names of people, places, organizations, and other entities of interest in text. This is a key component of many natural language processing applications. Using Large Language Models for Named-Entity Recognitions can be a very good application.
Below is an example of using BLOOMZ model for Named-Entity Recognition.
Fig. 3.3: Name-entity recognition using LLMs.
3.4 Audio and Voice Applications – ASR, TTS
ASR and TTS models based on sequence-to-sequence transformation pioneered by researchers at Meta (Facebook) have been adopted by authors to present a good demonstrations of TTS applications in Tamil, and other major Indian languages [15]. We note however number to words conversion remains a sore point in this implementation as
Clearly we can see the improved quality of AI/ML based TTS over unit-selection synthesis based approaches.
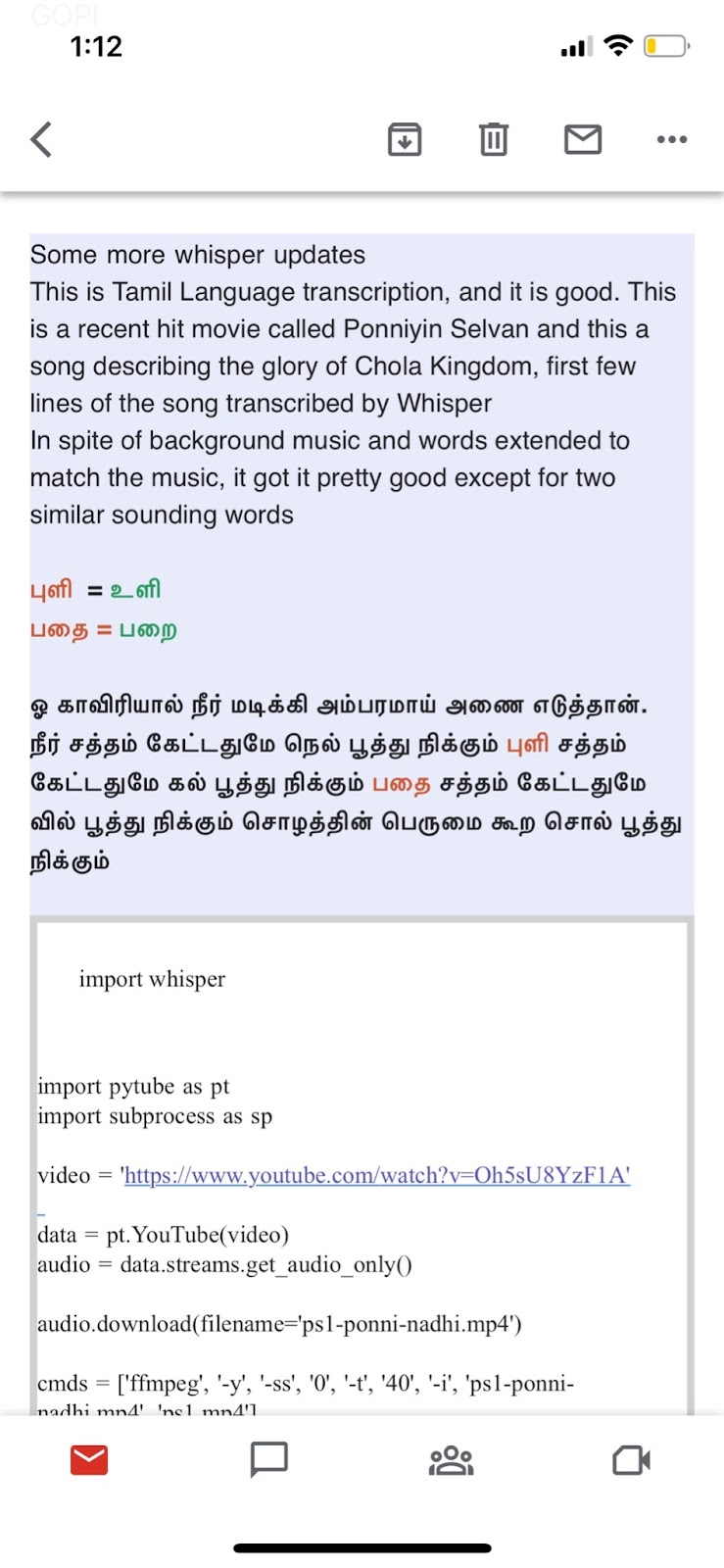
OpenAI’s Whisper [16], as reported in [18], is demonstrated to translate high-quality lyrical Tamil audio with transcription and errors highlighted in the following figure.
Fig 3.5: Experimental results of Malaikannan [18] using OpenAI Whisper for Tamil ASR based on the popular song “பொன்னி நதி” from the movie “பொன்னியின் செல்வன்.” This is showing low word-error rate 6.4%.
4 Tamil Tooling gaps
Our proposal is the following to address the gaps, and we also understand many of the steps are further problems on their own:
Develop a open-source toolbox for pre-training and task training specialization
Identify good components to base effort
Contribute engineering effort, testing, and validation
R&D – DataScience, Infra, AI framework
Engineering Validation – DataScience, Tamil language expertise
Engineering – packaging, documentation, distribution
Project management
Library to be liberally licensed MIT/BSD
Open-Source license for developed models
Find hardware resources for AI model pre-training etc.
Managed by a steering committee / nominated BDFL
Scope – decade time frame
Financial support for such a wide effort
4.1 Datasets related Tooling
Currently hosted datasets [1] not consumable in uniform interface for Torch or with TensorFlow in a uniform format; we have only raw data today.
4.2 Model Related Tooling
model attribute, training time, standardized accuracy metrics, training dataset, notions of biases etc. are absent
4.3 Compute related challenges
Free compute is limiting on what can be done; Google Cloud CoLaboratory is limited in credits that are freely available; training CNN or LSTM takes lot of time on laptop scale hardware.
There is a chronic need for special purpose AI Accelerators (GPU, RDUs, etc.) for large scale models pre-training; there needs to be efforts in private-public collaboration to subsidize cost and sponsorship these activities.
4.4 Problems and Biases
Just a decade ago the auto-complete in Google search query with the words “Tamil “ will always end with “Tigers,” limiting what an uninformed lay-person could learn about Tamil people, language or culture; which such a subjective bias has been removed it remains largely un-tested in various areas. This would be considered as harmful bias against Tamils by virtue of language marker in the discourse of [10].
Large language models (LLMs) are known to have problems with representing minorities along various margins, problems with performing math (calculators), potential to be environmentally harmful, repeat harmful stereotypes on minorities by age, nationality, race or other marking criteria [10], etc.
Language models exhibit a variety of expertise to work as auto-pilots in coding tasks [11], as email marketing assistants [12] etc. however as autonomous agents still much remains to be achieved [13] – current generation of AI models and agents are in rung-1 of 3-step ladder of causation [14] and act based on observation but not in a causal framework of learning which would be the creation of near-human level intelligence.
Specifically for Tamil language, as a largely under-resourced language, we find the nature of AI-systems to largely dependent on public data sets (uncurated) and few private data sets, and goodwill of giant corporations like Goolge or Meta (Facebook) to develop models for tasks. In such cases the pre-trained models are not qualified for biases. Additionally where data is not available or incorrect data is available the systems will not be able to reason correctly causing problematic consequences for applications of such AI models for Tamil community. Overall sufficient availability of compute, data, correctness and bias measures for Tamil tasks are needed to quantify bias in AI models.
Advent of generative AI models like DALL-E, Stable Diffusion etc. have created a chaotic situation of attribution, fair-use and copyright.
As a Tamil community we would want our real-world language, cultural, audio-visual, written and oral cultural milieu to be within the “in-distribution” of training set of the language/visual/multi-modal models for AI. When such a ecosystem of data driven AI modeling, and harm reducing systems exist perhaps someday we can hope to eliminate biases about individuals, groups, or minorities (by various labels) for creation of a oracular AI agents which can be native to Tamil.
5. Summary and Conclusions
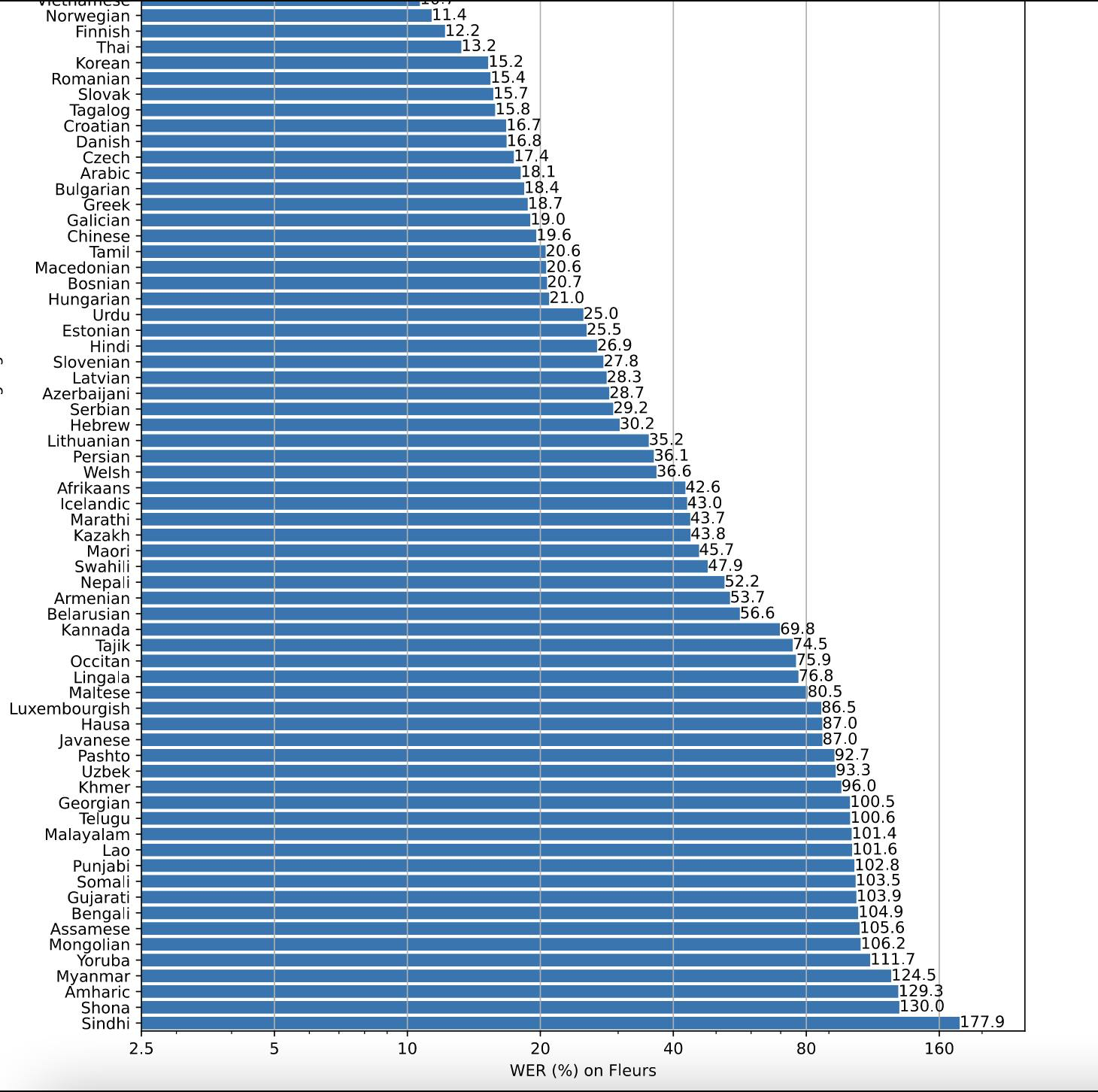
AI/ML systems rely of good data; we note dominance of Tamil data reflects in metrics like OpenAI’s Whisper (ASR model) performing on Tamil audio to have lowest word-error rate (at 20.6%) among Indian languages (even compared to Hindi at 26.9%) perhaps evidence of data prevalence and seeds of digitization and open-content in parallel corpora (audio + transcribed text) available in Tamil [16].
We have presented various aspects of AI/ML systems which can benefit the Tamil community in general and gaps in tooling which can accelerate the delivery of AI based applications in hands of general developer and community members, democratizing AI.
Briskilal, J. and Subalalitha, C.N., 2022. An ensemble model for classifying idioms and literal texts using BERT and RoBERTa. Information Processing & Management, 59(1), p.102756.
We propose the Tamil number forms are equivalent by isomorphism (single rule over all numbers to corresponding number forms) in Telugu, Kannada and Malayalam. The latter being almost indistinguishable from Tamil except for prosody; this is based on intuition of digit forms [1]. We further contend that algorithm for generating numerals in any of the four languages are structurally identical due to the equivalence of numerals in a abstract way. We propose common algorithm for generating and parsing number forms [2] in these languages to/from text and into audio TTS generation. These can be used in various applications like token-queue systems, spoken calculators, etc.
1 Introduction
It is quite well known the digits of Dravidian languages and even number forms are roughly symmetric [1]; however the structure of this symmetry is the subject of this paper and we demonstrate the structural symmetry can be applied to a computer algorithm for generation and parsing of numbers in these language simultaneously. To the best of our knowledge this is a first effort in such linguistic motivated algorithm.
2 Evidence
Using a publicly available corpora [3,4] and using Google translate [5] we have established parallel evidences of the sample number forms across the 4 southern languages. By inspection one can ascertain a rough correspondence; however this symmetry goes beyond rough correspondence as authors prior work [2] can be extended by parameterization with suitable suffixes and modifications by language family we posit a single algorithmic routine can perform both parsing and generation of a numbers.
எண் மதிப்பு
தமிழ்
மலயாளம்
கன்னடம்
தெலுங்கு
1
ஒன்று
onn
Ondu
Okaṭi
2
இரண்டு
raṇṭ
eraḍu
reṇḍu
3
மூன்று
mūnn
mūru
mūḍu
4
நான்கு
nāl
nālku
nālugu
5
ஐந்து
añc
aidu
aidu
6
ஆறு
āṟ
āru
āru
7
ஏழு
ēḻ
ēḷu
ēḍu
8
எட்டு
eṭṭ
eṇṭu
enimidi
9
ஒன்பது
ompat
ombattu
tom’midi
10
பத்து
patt
hattu
padi
11
பதினொன்று
patineānn
hannondu
padakoṇḍu
12
பன்னிரண்டு
pantraṇṭ
hanneraḍu
panneṇḍu
15
பதினைந்து
patinañc
hadinaidu
padihēnu
19
பெத்தொன்பது
patteāmpat
hattombattu
pantom’midi
20
இருபது
irupat
ippattu
iravai
30
முப்பது
muppat
mūvattu
muppai
40
நாற்பது
nālpat
nalavattu
nalabhai
50
ஐம்பது
ampat
aivattu
yābhai
75
எழுபத்தைந்து
eḻupatti añcu
eppattaidu
ḍebbai aidu
90
தொன்னூறு
teāḷḷāyiraṁ
ombainūru
tom’midi vandalu
99
தொன்னூற்றொன்பது
teāḷḷāyiratti ompat
ombainūra ombattu
tom’midi vandala tom’midi
100
நூறு
nūṟ
ondu nūru
vanda
200
இருநூறு
irunnūṟ
innūru
reṇḍu vandalu
500
ஐநூறு
aññūṟ
aidu nūru
aidu vandalu
1000
ஆயரம்
āyiraṁ
sāvira
veyyi
5000
ஐந்து ஆயரம்
ayyāyiraṁ
aidu sāvira
aidu vēlu
154999
ஒரு இலட்சத்து ஐம்பத்து நான்கு ஆயிரத்து தொள்ளாயிரத்து தொன்னூற்ற றொன்பது
oru lakṣatti ampattinālāyiratti teāḷḷāyiratti ompat
nūra aivattanālku sāvirada ombhainūra ombattu
nūṭa yābhai nālugu vēla tom’midi vandala tom’midi
Table 1: Parallel listing of number to words in Tamil, Malayalam, Kannada and Telugu
3 Algorithms
We modify the algorithm first presented in [2] for generating integral and floating point non-negative numbers for Tamil, but instead by view of symmetry in Tamil, Kannada, Malayalam and Telugu together called Dravidian languages (DL) we reorganize it as, follows,
Tamil Internet Conference, 2022. Thanjavur, India. 3 / 5
applied piece-meal to each of DL. In simpler terms we say the algorithms of [2] are parameterized by suffixes and prefixes specific to each DL but the overall structure remains the same by property of isomorphism. We note the steps for joining sections are to be handled in language specific way yet overall algorithm being invariant to source language.
3.1 Algorithm for Generating Numbers
Input: floating point number N Output: string of DL words T Algorithm:
Load list of prefix and string suffix for all DL number words – 63 words in all.
Find the quotient Q, remainder R for N divided by 1 crore, lakh, thousand, hundreds, or tens
If Q is zero set N=R and continue to 2.
Convert the quotient to words Ta. Take special care to handle 90s, 900s, 9000s, correctly.b. Take special care to handle number in 11-19.
Invoke same algorithm recursively for remainder R.
Concatenate results from 5 to T
Return T
3.2 Algorithm for Parsing Numbers
Input: string of DL list of words T Output: floating point number N Algorithm:
Load list of prefix and string suffix for all DL number words – 63 words in all.
Initialize N at 0
Create temporary stack S
FOR word W in T
IF W in stop words (crores, lakhs, thousands, hundreds, tens)a. Convert words in stack S into value and scale temporary result N using a helper routine which handles input upto value 100,0000.b. Empty stack S
ELSE: push W into S
END loop started at 4.
Stack S is mostly non-empty and you have to use a helperroutine to get the final portion of the number using the samehelper function in 5a.
Correctly parsed value is stored in N
4 Applications
Similar to the applications presented in [2] we can enable parameterized, by Dravidian Language (DL), a TTS generation, and calculator applications by reusing the algorithms of sec 3.1 and sec 3.2.
Fig 1: Organization of Speech input and Audio output calculator in each Dravidian Language (DL)
5 Summary and Conclusion
We have established algorithms to exploit the symmetry of number to words in Dravidian languages of Tamil, Malayalam, Kannada and Telugu for various applications; we demonstrated parameterized algorithm for generating and parsing number forms in these languages and provided a framework for applications like token-queue systems, spoken calculators, etc. leveraging this discoveries.
Open-Tamil project has expanded to provide its API as a web-service via https://tamilpesu.us website since 2018 [1]. In this article we share the process of migrating the deployment of this API server through cloud based app-platform with a service provider thereby providing significant advantages to users of site like: secure https access, quick time from code commit to deployment, and ease of maintenance for the project developers. We propose these identifications as easier tools for maintenance and growth of Tamil web applications and cause for wider adoption in our community.
1 Introduction
Open-Tamil is a Python library, used to develop Tamil NLP applications in Python. It provides all the basic functionalities to parse the unicode Tamil Text, easily, in Python among other text processing, and simple NLP functionalities [1a,b].
The way python handling the unicode tamil is not readable, by default. It operates on the low level unicode parsing. But, to achieve high level unicode handling parsing, we need an abstraction layer, so that any new developer can handle the tamil text as regular text using open-tamil library [1d].
1.1 TamilPesu.us
TamilPesu.us [1c] is the demonstrative web application for the features of the open-tamil python library. It has a the following features/components; the entire code of this application has been open-sourced for a few years now:
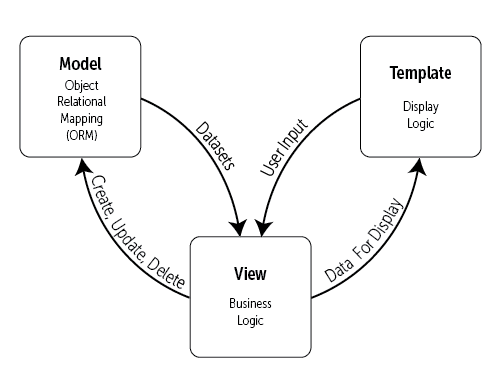
The architecture of Tamilpesu.us web application follows that of all sample Django applications – a model-view-template (MVT) as showin in Fig. 1 (Ref: 2[a])
Fig 1.1 Model-view-template of Django (figure courtesy of ref: 2[a])
The busines logic portion will provide the access to the various functionalities specified in sec. 1.1 via calls to the Open-Tamil library, Tamilsandhi library and Tamilinayavaani library.
1.3 API
The API capability of the Tamilpesu.us is useful for 3rd party sites to use the NLP and other functionalities in sec 1.1. Agrisakthi magazine and CloudsIndia [2b] developers use the text summarizer features of Tamilpesu.us.
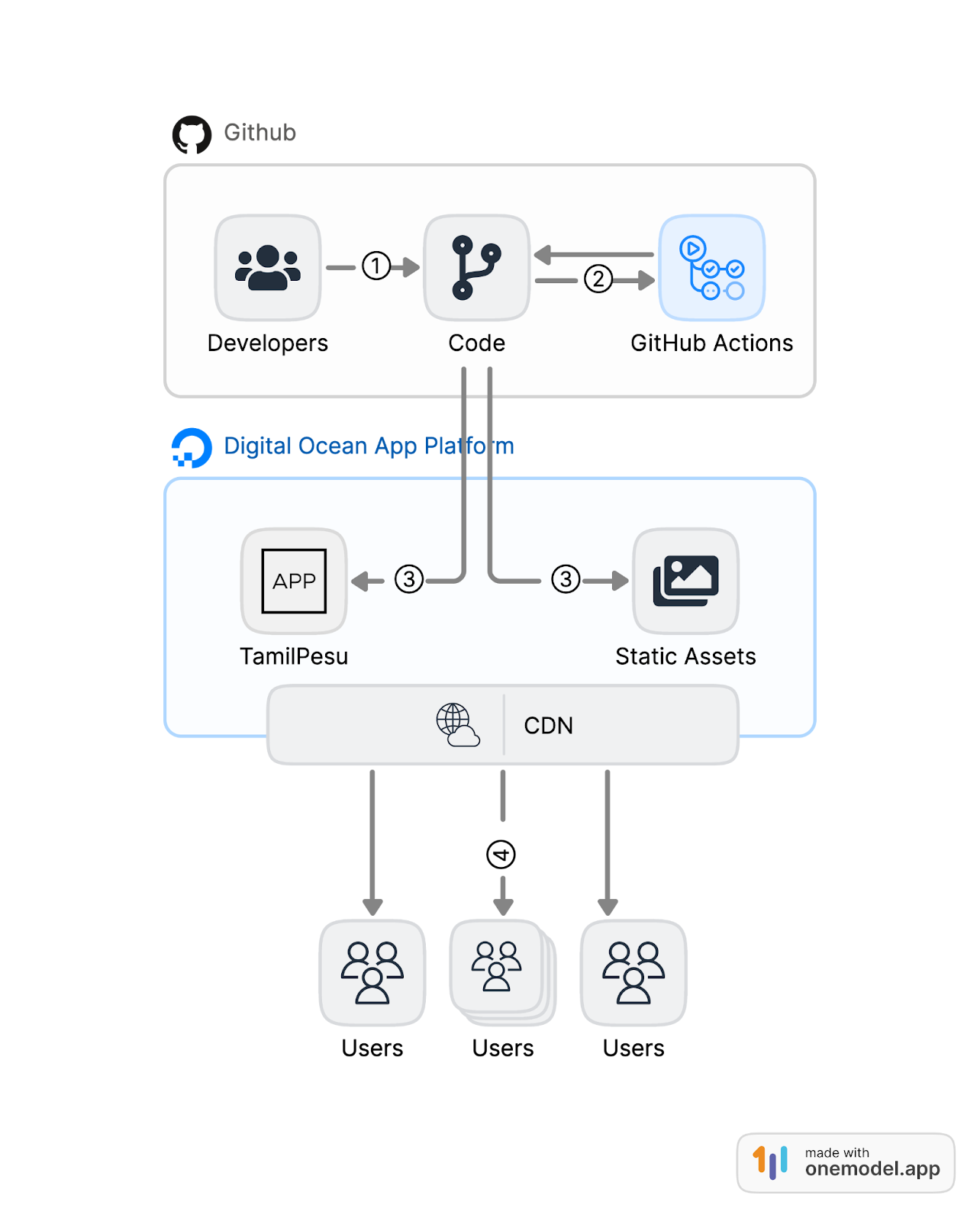
Figure 2(a): Deployment process of the code changes before adopting the app platform; 2(b) Present Deployment
The legacy deployment phase is a fully disconnected process from the development phase. The lifecycle of code change can be summarised into the following three stages.
Developers make code changes (Henceforth called simply, ‘Changes’) to fulfil feature additions, bug fixes and configuration changes for the TamilPesu app through a common repository hosted in Github. They propose Changes to the application in the form of Pull Requests.
When developers submit Pull Requests, the changes are sanity checked through GitHub Actions. GitHub Actions is a feature that can be used to implement automation tasks such as continuous integration, continuous testing and automated deployments. TamilPesu repository uses GitHub Actions to perform sanity checks against the Changes. For each of such Pull Requests, a sanity check is performed to eliminate errors before the Change is accepted and merged to the TamilPesu code base.
The Changes are made available to the application in the form of deployment. In order to perform a deployment, an administrator needs to log in to the Virtual Machine (VM) and obtain the latest code from Github. Once the new code is available, they need to perform certain manual operational tasks including Application server restarts, web server restarts, and database migrations that are required for the application. Administrators perform these deployments typically once a week.
3 Problems with the legacy deployment
Stages 1 and as a result Stage 2 are random events. Developers across the globe introduce Changes whenever they have time to contribute to the TamilPesu App. However, the deployment stage (Stage 3) is a periodic, less frequent event compared to the development events. Over a period of time, these changes accumulate and cause a drift between the server deployment and the application repository. When an error occurs during the deployment, it is difficult to find the root cause because we deploy multiple code changes simultaneously. Even though we perform sanity checks in the repository, they are lower-level checks for specific functionality. They don’t identify the cause of a deployment failure for the application as a whole.
When an administrator fixes the deployment, they usually make fixes in the form of code changes, directly in the server. These fixes should be backported to the repository. But since the deployment is manual and the changes must be made twice – once in the server and once in the repository, the backporting often gets neglected. This in turn causes another drift between the code in the server and the repository. Over a long period, the drift makes it impossible for the developers to fix the app and the administrators to do deployments consistently and reliably.
4 Deployment Process – Fully automated on Cloud
In the current architecture, we moved from deploying on top of the infrastructure as a service model to the platform as a service model. We replaced the Virtual machine which acted as a Web server and the application server, with a container-based platform service. There are two components that constitute the TamilPesu deployment. See figure 2.(b).
The application server component handles the server-side logic such as computing, API and networking.
Static file server which serves static assets such as CSS, javascript and images.
5 Continuous Deployment
From the legacy deployment model, stages 1 and 2 stay as they are. But the key difference is that now the deployment from the code base – stage 3 is automatic. We configured the digital ocean app to look for changes in the production branch of the TamilPesu repository. As soon as the code is merged into the production branch, Digital ocean triggers a deployment.
The manual steps required to deploy the code in the application server are automated using a Dockerfile. Dockerfile is a specification of how to build and run the application from the code. The app platform takes advantage of the existing Dockerfile from the repository and uses it to build and deploy the application.
5.1 Zero Configuration Drifts
As a result of continuous deployment, the drift between the deployment and the repository is fully eradicated. There is a one-to-one relationship between an app deployment and a commit in the production branch of the TamilPesu repository.
5.2 Quick Deployment
Since there are no manual works, the deployment time is reduced significantly. Typically it take about 3 minutes for the deployment to be complete and the new version of website available for public use.
5.3 High Uptime
In case of deployment errors, the previous version of the website is kept functional serving the website traffic. This ensures the application to be available even in case of build failures. The app platform also supports a manual rollback feature to previous versions.
5.4 Monitoring and Alerting on Failures
The app platform provides basic resource usage monitoring such as CPU, Memory and network utilization. In addition, any build or deployment failure can be configured to trigger an alert email or Slack message.
5.5 HTTPS
The app deployment provides a TLS certificates for the domain name and enable them without any additonal configurations or costs.
5.6 CDN
The advantage of adding a separate static component is that these resources are served using a Content delivery network (CDN). A content delivery network is a caching service used to distribute static content across geographical regions and serve them at a high speed for the users local to that region. This significantly reduced the app loading time for users across the globe.
5.7 Scaling
In order to respond to increased app usage, we might need to scale the application horizontally. In app platform, we can increase the application containers to meet the demands of the application usage easily. The scaling completes typically within a minute.
5.8 Other Deployment Options
Digital Ocean’s app platfom is one of the platform as a services provider. There are the following alternate services where we can deploy a similar architecture.
Kubernetes
AWS fargate
AWS EKS
Heroku
pythonhosted
5.9 Applications
In our case we were able to deploy the Open-Tamil code functionality to show Date-time in Tamil words as a Tamilpesu web-app in few hours of coding to enable the change.
Figure 5: Tamil Date-Time function integrated from open-tamil and published to https://tamilpesu.us using app-platform auto-deploy.
6. Summary and Conclusions
In summary we have migrated Tamilpesu from manual deployment to git-action push-to-deploy methodology using the Digital Ocean app-platform where code changes are seamlessly and effectively deployed to customer. We think this is a good technology suitable for adoption by the wide Tamil developer community.
References:
(a) Syed Abuthahir et-al,”Growth and Evolution of Open-Tamil,” Tamil Internet Conference (2018).
Udhayakumar, S. P., and M. Sivasubramanian. “Shift Left: Strengthening the Requirements Elicitation Process for Improving Quality Software in Software Development Projects.” (2022).
Mulerikkal, Jaison Paul, and Ibrahim Khalil. “An architecture for distributed content delivery network.” 2007 15th IEEE International Conference on Networks. IEEE, 2007.